流(Stream)
一、规范(Specification)
Stream接口是一个用来承载负载(payload)的简单握手协议。例如, 它可以用来对FIFO压入或弹出数据、发送请求给UART控制器等等。
| 信号 | 类型 | 驱动 | 描述 | Don't care 条件 |
|---|---|---|---|---|
| valid | Bool | Master | 当置高时, 说明负载通过该接口 | |
| ready | Bool | Slave | 当置低时, 表明该slave口不接收传输(transaction) | valid为低时, dont care |
| payload | T | Master | 负载任务的内容 | valid为低时, dont care |
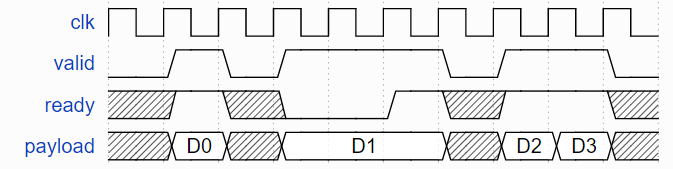
在SpinalHDL中有如下应用例子:
class StreamFifo[T <: Data](dataType: T, depth: Int) extends Component {
val io = new Bundle {
val push = slave Stream (dataType)
val pop = master Stream (dataType)
}
...
}
class StreamArbiter[T <: Data](dataType: T,portCount: Int) extends Component {
val io = new Bundle {
val inputs = Vec(slave Stream (dataType),portCount)
val output = master Stream (dataType)
}
...
}
备注:当
valid高而ready低时, 每个slave可以又或不可以允许有效负载发生变化(视情况而定)。例如:
没有锁逻辑的优先级仲裁器可以从一个输入切换到另一个输入(这将改变负载)
UART控制器可以直接使用写端口来驱动UART引脚, 并且只在传输结束时完成数据交换(consume the transaction)。需要注意。
二、语义(Semantics)
当手动读取或驱动一个流中的信号时需要牢记:
当
valid被置为有效后, 它只有当目前的负载已经被使用后才可以被置为无效。这意味着valid只有在slave口通过置高ready来完成一次读操作后的下一个周期, 才可以被置为0。与
valid相反的是,ready是可以随时改变的数据的传输只有当
valid和ready同时置高时才会发生一个流的
valid一定不能和ready以组合的方式连接, 它们之间的任何路径都应该是通过寄存器的。推荐在
valid和ready之间没有任何依赖(连接路径)
三、函数(Functions)
| 句式 | 描述 | 返回值 | 延迟 |
|---|---|---|---|
| Stream(type : Data) | 建立一个给定类型的流 | Stream[T] | |
| master/slave Stream(type : Data) | 建立一个给定类型的流, 并根据给定的IO设置初始化 | Stream[T] | |
| x.fire | 当消息在总线上完成了传递或者说握手完成(valid && ready)则返回true | Bool | |
| x.isStall | 当消息堵塞在总线上或者说握手未完成(valid && !ready)则返回true | Bool | |
| x.queue(size:Int) | 返回一个通过FIFO与x相连的流 | Stream[T] | 2 |
| x.m2sPipe() x.stage() |
返回一个由x通过寄存器驱动的流 Cost = (payload width + 1) flop flop |
Stream[T] | 1 |
| x.s2mPipe() | 返回一个由x驱动的流。 ready路径通过寄存器阶段分割。 Cost = (payload width + 1) flop flop |
Stream[T] | 0 |
| x.halfPipe() | 返回一个由x驱动的流。 valid/ready/payload路径通过一些寄存器分割。 Cost = (payload width + 2) flip flop, bandwidth divided by two |
Stream[T] | 1 |
| x << y y >> x |
把y连接到x | 0 | |
| x <-< y y >-> x |
通过m2sPipe把y连接到x | 1 | |
| x y >/> x | 通过s2mPipe把y连接到x | 0 | |
| x <-/< y >/-> x |
通过s2mPipe().m2sPipe()把y连接到x, 意味着x和y之间无组合路径 | 1 | |
| x.haltWhen(cond : Bool) | 返回一个连接到x的流, 并且当cond为true时停顿 | Stream[T] | 0 |
| x.throwWhen(cond : Bool) | 返回一个连接到x的流, 并且当cond为true时抛弃需要交换的数据 | Stream[T] | 0 |
下方的代码将会产生如下图所示的逻辑电路:

case class RGB(channelWidth : Int) extends Bundle{
val red = UInt(channelWidth bits)
val green = UInt(channelWidth bits)
val blue = UInt(channelWidth bits)
def isBlack : Bool = red === 0 && green === 0 && blue === 0
}
val source = Stream(RGB(8))
val sink = Stream(RGB(8))
sink <-< source.throwWhen(source.payload.isBlack)
上述Scala代码生成的Verilog电路如下:
// Generator : SpinalHDL v1.6.0 git head : 73c8d8e2b86b45646e9d0b2e729291f2b65e6be3
// Component : RGBStream
module RGBStream (
input clk,
input reset
);
wire source_valid;
reg source_ready;
wire [7:0] source_payload_red;
wire [7:0] source_payload_green;
wire [7:0] source_payload_blue;
wire sink_valid;
wire sink_ready;
wire [7:0] sink_payload_red;
wire [7:0] sink_payload_green;
wire [7:0] sink_payload_blue;
wire when_Stream_l408;
reg source_thrown_valid;
reg source_thrown_ready;
wire [7:0] source_thrown_payload_red;
wire [7:0] source_thrown_payload_green;
wire [7:0] source_thrown_payload_blue;
wire source_thrown_m2sPipe_valid;
wire source_thrown_m2sPipe_ready;
wire [7:0] source_thrown_m2sPipe_payload_red;
wire [7:0] source_thrown_m2sPipe_payload_green;
wire [7:0] source_thrown_m2sPipe_payload_blue;
reg source_thrown_rValid;
reg [7:0] source_thrown_rData_red;
reg [7:0] source_thrown_rData_green;
reg [7:0] source_thrown_rData_blue;
wire when_Stream_l342;
assign when_Stream_l408 = (((source_payload_red == 8'h0) && (source_payload_green == 8'h0)) && (source_payload_blue == 8'h0));
always @(*) begin
source_thrown_valid = source_valid;
if(when_Stream_l408) begin
source_thrown_valid = 1'b0;
end
end
always @(*) begin
source_ready = source_thrown_ready;
if(when_Stream_l408) begin
source_ready = 1'b1;
end
end
assign source_thrown_payload_red = source_payload_red;
assign source_thrown_payload_green = source_payload_green;
assign source_thrown_payload_blue = source_payload_blue;
always @(*) begin
source_thrown_ready = source_thrown_m2sPipe_ready;
if(when_Stream_l342) begin
source_thrown_ready = 1'b1;
end
end
assign when_Stream_l342 = (! source_thrown_m2sPipe_valid);
assign source_thrown_m2sPipe_valid = source_thrown_rValid;
assign source_thrown_m2sPipe_payload_red = source_thrown_rData_red;
assign source_thrown_m2sPipe_payload_green = source_thrown_rData_green;
assign source_thrown_m2sPipe_payload_blue = source_thrown_rData_blue;
assign sink_valid = source_thrown_m2sPipe_valid;
assign source_thrown_m2sPipe_ready = sink_ready;
assign sink_payload_red = source_thrown_m2sPipe_payload_red;
assign sink_payload_green = source_thrown_m2sPipe_payload_green;
assign sink_payload_blue = source_thrown_m2sPipe_payload_blue;
always @(posedge clk or posedge reset) begin
if(reset) begin
source_thrown_rValid <= 1'b0;
end else begin
if(source_thrown_ready) begin
source_thrown_rValid <= source_thrown_valid;
end
end
end
always @(posedge clk) begin
if(source_thrown_ready) begin
source_thrown_rData_red <= source_thrown_payload_red;
source_thrown_rData_green <= source_thrown_payload_green;
source_thrown_rData_blue <= source_thrown_payload_blue;
end
end
endmodule
四、工具(Utils)
Stream中有许多工具可以与用户设计中的流总线(Stream bus)结合, 本章将会介绍他们。
流式FIFO(StreamFifo)
用户可以在每个流上调用.queue(size)来获得一个缓冲流(buffered stream)。但是也可以实例化FIFO组件本身:
val streamA,streamB = Stream(Bits(8 bits)) //... val myFifo = StreamFifo( dataType = Bits(8 bits), depth = 128 ) myFifo.io.push << streamA myFifo.io.pop >> streamB
Verilog:
module StreamFifo ( input io_push_valid, output io_push_ready, input [7:0] io_push_payload, output io_pop_valid, input io_pop_ready, output [7:0] io_pop_payload, input io_flush, output [7:0] io_occupancy, output [7:0] io_availability, input clk, input reset ); reg [7:0] _zz_logic_ram_port0; wire [6:0] _zz_logic_pushPtr_valueNext; wire [0:0] _zz_logic_pushPtr_valueNext_1; wire [6:0] _zz_logic_popPtr_valueNext; wire [0:0] _zz_logic_popPtr_valueNext_1; wire _zz_logic_ram_port; wire _zz_io_pop_payload; wire [6:0] _zz_io_availability; reg _zz_1; reg logic_pushPtr_willIncrement; reg logic_pushPtr_willClear; reg [6:0] logic_pushPtr_valueNext; reg [6:0] logic_pushPtr_value; wire logic_pushPtr_willOverflowIfInc; wire logic_pushPtr_willOverflow; reg logic_popPtr_willIncrement; reg logic_popPtr_willClear; reg [6:0] logic_popPtr_valueNext; reg [6:0] logic_popPtr_value; wire logic_popPtr_willOverflowIfInc; wire logic_popPtr_willOverflow; wire logic_ptrMatch; reg logic_risingOccupancy; wire logic_pushing; wire logic_popping; wire logic_empty; wire logic_full; reg _zz_io_pop_valid; wire when_Stream_l1078; wire [6:0] logic_ptrDif; reg [7:0] logic_ram [0:127]; assign _zz_logic_pushPtr_valueNext_1 = logic_pushPtr_willIncrement; assign _zz_logic_pushPtr_valueNext = {6'd0, _zz_logic_pushPtr_valueNext_1}; assign _zz_logic_popPtr_valueNext_1 = logic_popPtr_willIncrement; assign _zz_logic_popPtr_valueNext = {6'd0, _zz_logic_popPtr_valueNext_1}; assign _zz_io_availability = (logic_popPtr_value - logic_pushPtr_value); assign _zz_io_pop_payload = 1'b1; always @(posedge clk) begin if(_zz_io_pop_payload) begin _zz_logic_ram_port0 <= logic_ram[logic_popPtr_valueNext]; end end always @(posedge clk) begin if(_zz_1) begin logic_ram[logic_pushPtr_value] <= io_push_payload; end end always @(*) begin _zz_1 = 1'b0; if(logic_pushing) begin _zz_1 = 1'b1; end end always @(*) begin logic_pushPtr_willIncrement = 1'b0; if(logic_pushing) begin logic_pushPtr_willIncrement = 1'b1; end end always @(*) begin logic_pushPtr_willClear = 1'b0; if(io_flush) begin logic_pushPtr_willClear = 1'b1; end end assign logic_pushPtr_willOverflowIfInc = (logic_pushPtr_value == 7'h7f); assign logic_pushPtr_willOverflow = (logic_pushPtr_willOverflowIfInc && logic_pushPtr_willIncrement); always @(*) begin logic_pushPtr_valueNext = (logic_pushPtr_value + _zz_logic_pushPtr_valueNext); if(logic_pushPtr_willClear) begin logic_pushPtr_valueNext = 7'h0; end end always @(*) begin logic_popPtr_willIncrement = 1'b0; if(logic_popping) begin logic_popPtr_willIncrement = 1'b1; end end always @(*) begin logic_popPtr_willClear = 1'b0; if(io_flush) begin logic_popPtr_willClear = 1'b1; end end assign logic_popPtr_willOverflowIfInc = (logic_popPtr_value == 7'h7f); assign logic_popPtr_willOverflow = (logic_popPtr_willOverflowIfInc && logic_popPtr_willIncrement); always @(*) begin logic_popPtr_valueNext = (logic_popPtr_value + _zz_logic_popPtr_valueNext); if(logic_popPtr_willClear) begin logic_popPtr_valueNext = 7'h0; end end assign logic_ptrMatch = (logic_pushPtr_value == logic_popPtr_value); assign logic_pushing = (io_push_valid && io_push_ready); assign logic_popping = (io_pop_valid && io_pop_ready); assign logic_empty = (logic_ptrMatch && (! logic_risingOccupancy)); assign logic_full = (logic_ptrMatch && logic_risingOccupancy); assign io_push_ready = (! logic_full); assign io_pop_valid = ((! logic_empty) && (! (_zz_io_pop_valid && (! logic_full)))); assign io_pop_payload = _zz_logic_ram_port0; assign when_Stream_l1078 = (logic_pushing != logic_popping); assign logic_ptrDif = (logic_pushPtr_value - logic_popPtr_value); assign io_occupancy = {(logic_risingOccupancy && logic_ptrMatch),logic_ptrDif}; assign io_availability = {((! logic_risingOccupancy) && logic_ptrMatch),_zz_io_availability}; always @(posedge clk or posedge reset) begin if(reset) begin logic_pushPtr_value <= 7'h0; logic_popPtr_value <= 7'h0; logic_risingOccupancy <= 1'b0; _zz_io_pop_valid <= 1'b0; end else begin logic_pushPtr_value <= logic_pushPtr_valueNext; logic_popPtr_value <= logic_popPtr_valueNext; _zz_io_pop_valid <= (logic_popPtr_valueNext == logic_pushPtr_value); if(when_Stream_l1078) begin logic_risingOccupancy <= logic_pushing; end if(io_flush) begin logic_risingOccupancy <= 1'b0; end end end endmodule
| 参数名 | 类型 | 描述 |
|---|---|---|
| dataType | T | 流式FIFO上负载数据的类型 |
| depth | Int | 存储数据的存储大小 |
| IO口名 | 类型 | 描述 |
|---|---|---|
| push | Stream[T] | 用来向流式FIFO中压入数据 |
| pop | Stream[T] | 用来从流式FIFO中弹出数据 |
| flush | Bool | 用来清空流式FIFO中的所有数据 |
| occupancy | UInt of log2Up(depth + 1) bits | 反映内部存储占用情况 |
流式FIFOCC(StreamFifoCC)
用户可以通过如下方式定义一个双时钟域FIFO:
val clockA = ClockDomain(???) val clockB = ClockDomain(???) val streamA,streamB = Stream(Bits(8 bits)) //... val myFifo = StreamFifoCC( dataType = Bits(8 bits), depth = 128, pushClock = clockA, popClock = clockB ) myFifo.io.push << streamA myFifo.io.pop >> streamB
| 参数名 | 类型 | 描述 |
|---|---|---|
| dataType | T | 流式FIFO上负载数据的类型 |
| depth | Int | 存储数据的存储大小 |
| pushClock | ClockDomain | 存入数据端使用的时钟域 |
| popClock | ClockDomain | 取出数据端使用的时钟域 |
| IO口名 | 类型 | 描述 |
|---|---|---|
| push | Stream[T] | 用来向流式FIFO中压入数据 |
| pop | Stream[T] | 用来从流式FIFO中弹出数据 |
| pushOccupancy | UInt of log2Up(depth + 1) bits | 反映内部存储占用情况(从存入数据角度) |
| popOccupancy | UInt of log2Up(depth + 1) bits | 反映内部存储占用情况(从取出数据角度) |
StreamCCByToggle
该方法基于信号切换来生成连接跨时钟域的流的组件。这种方法生成的跨时钟域桥占用较小的面积, 但同时其带宽较低。
val clockA = ClockDomain(???) val clockB = ClockDomain(???) val streamA,streamB = Stream(Bits(8 bits)) //... val bridge = StreamCCByToggle( dataType = Bits(8 bits), inputClock = clockA, outputClock = clockB ) bridge.io.input << streamA bridge.io.output >> streamB
| 参数名 | 类型 | 描述 | | :———: | :———: | :———————-: | | dataType | T | 流式FIFO上负载数据的类型 | | inputClock | ClockDomain | 存入数据端使用的时钟域 | | outputClock | ClockDomain | 取出数据端使用的时钟域 |
| IO口名 | 类型 | 描述 |
|---|---|---|
| input | Stream[T] | 用来向流式FIFO中压入数据 |
| output | Stream[T] | 用来从流式FIFO中弹出数据 |
另外用户也可使用更简短的语句来直接生成所需的跨时钟流:
val clockA = ClockDomain(???)
val clockB = ClockDomain(???)
val streamA = Stream(Bits(8 bits))
val streamB = StreamCCByToggle(
input = streamA,
inputClock = clockA,
outputClock = clockB
)
流位宽适应器(StreamWidthAdapter)
该组件会使得输入流与输出流的位宽相匹配。当输出流
outStream的负载的位宽比inStream的位宽更大时, 会通过将多个输入传输任务结合成一个的操作来匹配输出的大位宽;相反, 如果输出位宽大于输入位宽, 则一个输入的传输任务会被分割成多个输出传输任务以匹配输出的小位宽。在最好的情况下, 输入
inStream负载的位宽应该是输出outStream负载的整数倍, 如下方代码所示:val inStream = Stream(Bits(8 bits)) val outStream = Stream(Bits(16 bits)) val adapter = StreamWidthAdapter(inStream, outStream)
Verilog:
module MyTopLevel ( input io_cond0, input io_cond1, output io_flag, output [7:0] io_state, input clk, input reset ); wire [15:0] _zz_outStream_payload_1; wire inStream_valid; wire inStream_ready; wire [7:0] inStream_payload; wire outStream_valid; wire outStream_ready; wire [15:0] outStream_payload; wire inStream_fire; reg _zz_inStream_ready; reg [0:0] _zz_inStream_ready_1; reg [0:0] _zz_inStream_ready_2; wire _zz_inStream_ready_3; reg [7:0] _zz_outStream_payload; wire inStream_fire_1; assign _zz_outStream_payload_1 = {inStream_payload,_zz_outStream_payload}; assign inStream_fire = (inStream_valid && inStream_ready); always @(*) begin _zz_inStream_ready = 1'b0; if(inStream_fire) begin _zz_inStream_ready = 1'b1; end end assign _zz_inStream_ready_3 = (_zz_inStream_ready_2 == 1'b1); always @(*) begin _zz_inStream_ready_1 = (_zz_inStream_ready_2 + _zz_inStream_ready); if(1'b0) begin _zz_inStream_ready_1 = 1'b0; end end assign inStream_fire_1 = (inStream_valid && inStream_ready); assign outStream_valid = (inStream_valid && _zz_inStream_ready_3); assign outStream_payload = _zz_outStream_payload_1; assign inStream_ready = (! ((! outStream_ready) && _zz_inStream_ready_3)); always @(posedge clk or posedge reset) begin if(reset) begin _zz_inStream_ready_2 <= 1'b0; end else begin _zz_inStream_ready_2 <= _zz_inStream_ready_1; end end always @(posedge clk) begin if(inStream_fire_1) begin _zz_outStream_payload <= inStream_payload; end end endmodule
如上方例子所示, 两个
inStream的传输将会被结合成一个outStream传输, 并且第一个inStream的传输会被默认放置在输出负载的低比特。如果输入传输任务负载的期望顺序和默认设置不同, 这里有一个例子:
val inStream = Stream(Bits(8 bits)) val outStream = Stream(Bits(16 bits)) val adapter = StreamWidthAdapter(inStream, outStream, order = SlicesOrder.HIGHER_FIRST)
同时还有一个与
ORDER具有相同效果的名为endianness的传统参数。当endianness的值为LITTLE时, 它和order的LOWER_FIRST值等同。同理其BIG值和HIGHER_FIRST等同。padding参数是一个可选择的布尔逻辑值, 其可以决定该适应器能否接受输入与输出负载位宽之间的非整数倍数关系。流仲裁器(StreamArbiter)
当用户有多个流而且希望能够仲裁它们并驱动单个流, 这时可以使用StreamArbiterFactory。
val streamA, streamB, streamC = Stream(Bits(8 bits)) val arbitredABC = StreamArbiterFactory.roundRobin.onArgs(streamA, streamB, streamC) val streamD, streamE, streamF = Stream(Bits(8 bits)) val arbitredDEF = StreamArbiterFactory.lowerFirst.noLock.onArgs(streamD, streamE, streamF)
| 仲裁函数 | 描述 |
|---|---|
| lowerFirst | 低端口的优先级大于高端口 |
| roundRobin | 公平轮询仲裁 |
| sequentialOrder | 按照顺序次序遍历任务。第一个传输来自于端口零, 然后依次执行... |
| 锁函数 | 描述 |
|---|---|
| noLock | 端口选择在每个周期都可以改变, 即使被选择的端口的传输没有执行 |
| transactionLock | 端口选择被锁定直到端口的数据交换完成 |
| fragmentLock | 可用来仲裁Stream[Flow[T]]。在这个模式下, 端口选择被锁定直到被选择的端口完成信号突发(burst)(last=True) |
| 生成函数 | 返回值 |
|---|---|
| on(inputs : Seq[Stream[T]]) | Stream[T] |
| onArgs(inputs : Stream[T]*) | Stream[T] |
- StreamJoin
该工具接受多个输入流, 并等待它们全部触发, 随后全部通过所有输入流。
val cmdJoin = Stream(Cmd())
cmdJoin.arbitrationFrom(StreamJoin.arg(cmdABuffer, cmdBBuffer))
流式叉(StreamFork)
StreamFork将会对每个输入数据进行克隆并分配到所有的输出流中。如果同步为true, 则所有的输出流会同时激活, 意味着流会停滞直到所有的输出流准备就绪。如果同步信号为false, 则在额外的一个触发器的开销下,每次只有一个输出流准备就绪。输入的流将会被堵塞直到所有的输出流已经处理过每个项目。
val inputStream = Stream(Bits(8 bits)) val (outputstream1, outputstream2) = StreamFork2(inputStream, synchronous=false)
或者是:
val inputStream = Stream(Bits(8 bits)) val outputStreams = StreamFork(inputStream,portCount=2, synchronous=true)
流顺序调度器(StreamDispatcherSequencial)
该工具会将其输入流以顺序次序路由(route)给
outputCount流。val inputStream = Stream(Bits(8 bits)) val dispatchedStreams = StreamDispatcherSequencial( input = inputStream, outputCount = 3 )